Face tracking : implémentation de la méthode de Viola & Jones en C++

Sommaire
Bonjour à tous.
Aujourd'hui, un tuto un peu particulier puis-ce qu'il s'agit de mon projet de fin d'études. Le but est de faire de la détection de visage dans une vidéo à l'aide de la méthode de Viola & Jones.
Comme ça peut paraître un peu flou au premier abord, voici une vidéo de démonstration :
La source vidéo un est un sketch des Inconnus. La vidéo est disponible sur Youtube.
Comme vous pouvez le voir, le but est de détecter où se situe le visage dans la vidéo et de placer une marqueur, typiquement un rectangle, à l'endroit où il est détecté. C'est globalement ce que l'on peut observer avec des appareils photo numériques implémentant la détection de visage.
Pour ce tuto vous allez avoir besoin de :
- Un ordinateur Windows ou Linux
- Une webcam
- Un classifieur
Sachez qu'il n'est pas nécessaire de comprendre comment fonctionne la méthode pour l'implémenter. Un simple copier/coller compiler/exécuter suffi à obtenir le résultat présenté dans la vidéo mais je trouve dommage de ne pas chercher à comprendre ce que l'on code ;)
Allez on commence !
1. Explication de la méthode de Viola & Jones
1.1 Principe
La méthode de Viola & Jones consiste à balayer une image à l'aide d'une fenêtre de détection de taille initiale 24px par 24px (dans l'algorithme original) et de déterminer si un visage y est présent. Lorsque l'image a été parcourue entièrement, la taille de la fenêtre est augmentée et le balayage recommence, jusqu'à ce que la fenêtre fasse la taille de l'image. L'augmentation de la taille de la fenêtre se fait par un facteur multiplicatif de 1,25.
Le balayage, quant à lui, consiste simplement à décaler la fenêtre d'un pixel. Ce décalage peut être changé afin d'accélérer le processus, mais un décalage d'un pixel assure une précision maximale.
Cette méthode est une approche basée sur l'apparence, qui consiste à parcourir l'ensemble de l'image en calculant un certain nombre de caractéristiques dans des zones rectangulaires qui se chevauchent. Elle a la particularité d'utiliser des caractéristiques très simples mais très nombreuses.
Il existe d'autres méthodes mais celle de Viola & Jones est la plus performante à l'heure actuelle. Ce qui la différencie des autres est notamment :
- l'utilisation d'images intégrales qui permettent de calculer plus rapidement les caractéristiques
- la sélection par boosting des caractéristiques
- la combinaison en cascade de classifieurs boostés, apportant un net gain de temps d'exécution
1.2 Apprentissage du classifeur
Une étape préliminaire et très importante est l'apprentissage du classifieur. Il s'agit d'entraîner le classifieur afin de le sensibiliser à ce que l'on veut détecter, ici des visages. Pour cela, il est mis dans deux situations.
La première où une énorme quantité de cas positifs lui sont présentés et la deuxiàme où, à l'inverse, une énorme quantité de cas négatifs lui sont présentés. Concrètement, une banque d'images contenant des visages de personnes est passée en revue afin d'entraîner le classifieur. Ensuite, une banque d'images ne contenant pas de visages humains est passée.
Dans le cas présent, Viola et Jones ont entraînés leur classifieur à l'aide d'une banque d'images du MIT. Il en résulte un classifieur sensibles aux visages humain. Il se présente sous la forme d'un fichier .xml.
Dans l'absolu, on serait en mesure de détecter n'importe quel signe distinctif à partir d'un classifieur entrainé à cela.
Voici un tutoriel (en anglais) qui explique comment construire son propre classifieur : http://note.sonots.com/SciSoftware/haartraining.html.
1.3 Les caractéristiques
C'est bien beau tout ça, mais c'est quoi concrètement une caractéristique ?
Une caractéristique est une représentation synthétique et informative, calculée à partir des valeurs des pixels. Les caractéristiques utilisées ici sont les caractéristiques pseudo-haar. Elle sont calculées par la différence des sommes de pixels de deux ou plusieurs zones rectangulaires adjacentes.
Ca veut dire quoi ce charabia ?
Penons un exemple. Voici deux zones rectangulaires adjacentes, la première en blanc, la deuxième en noire :
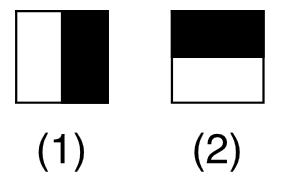
Les caractéristique seraient calculées en soustrayant la somme des pixels noirs à la somme des pixels blancs. Pas si compliqué que ça finalement !
Les caractéristiques sont calculées à toutes les positions et à toutes les échelles dans une fenêtre de détection de petite taille, typiquement de 24x24 pixels ou de 20x15 pixels. Un très grand nombre de caractéristiques par fenêtre est ainsi généré, Viola et Jones donnant l'exemple d'une fenêtre de taille 24 x 24 qui génère environ 160 000 caractéristiques.
L'image précédente présente des caractéristiques pseudo-haar à seulement deux caractéristiques mais il en existe d'autres, allant de 4 à 14, et avec différentes orientations.
Malheureusement, le calcul de ces caractéristiques de manière "classique" coûte cher en terme de ressources processeur, c'est là qu'interviennent les images intégrales.
1.4 Les images intégrales
Comme je vous l'ai dis précédemment, les images intégrales permettent de gagner du temps quant au calcul des caractéristiques. Il s'agit d'une image construite à partir de l'image d'origine, et de même taille qu'elle. Elle contient en chacun de ses points la somme des pixels situés au-dessus et à gauche du pixel courant. Regardez cette figure :
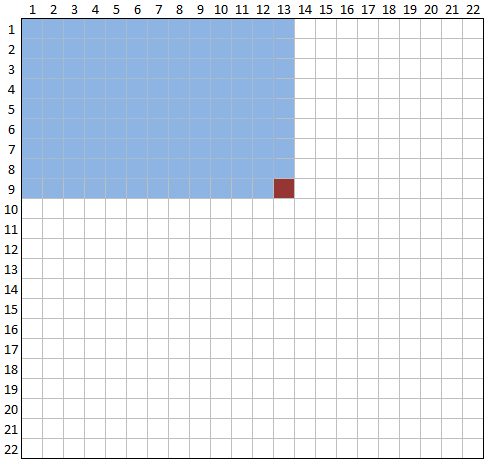
Le pixel rouge est égale à la somme de tous les pixels bleu, soient ceux à gauche et au dessus ;)
Ok, mais je ne vois pas en quoi ça nous aide à calculer les caractéristiques ...
Prenons un exemple. Nous souhaitons calcuer la sommes des pixels de la zone rectangulaire ABCD suivante :
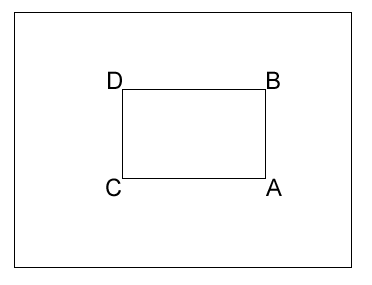
Grâce à l'image intégrale, nous connaissons la valeur de la sommes des pixels en chacun des quatres points. Il suffit donc de faire : A-B-C+D.
En seulement trois opérations nous avons réussi à calculer notre somme de pixels ! Ainsi, on est en mesure de trouver la somme de pixels de n'importe quelle zone rectangulaire de l'image en seulement 3 opérations et 4 accès à l'image intégrale (un accès par point).
Une caractéristique pseudo-Haar à deux rectangles peut alors être déterminée en seulement 6 accès (2 points sont partagés) à l'image, et une caractéristique à 3 rectangles en seulement 8 accès.
1.5 Sélection par boosting
Nous arrivons maintenant à la dernière partie concernant la théorie : la sélection par boosting !
La sélection par boosting consiste à utiliser plusieurs classifieurs "faibles" mis en cascade plutôt que d'utiliser un seul classifieur "fort". En effet, avec un seul classifieur dit "fort" qui se présenterait de la sorte :
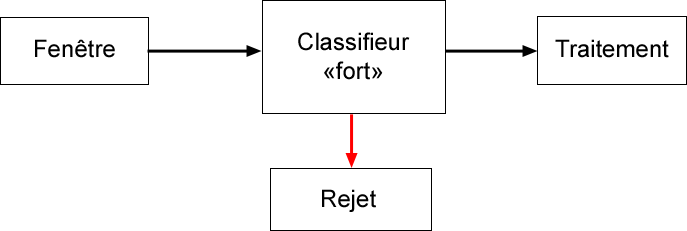
Il faudrait attendre que le classifieur est analysé toute la fenêtre afin de savoir si un visage est présent dans l'image ou non. Une mise en cascade de classifieurs dont le critère de sélection serait moins sévère se présenterait de la sorte :
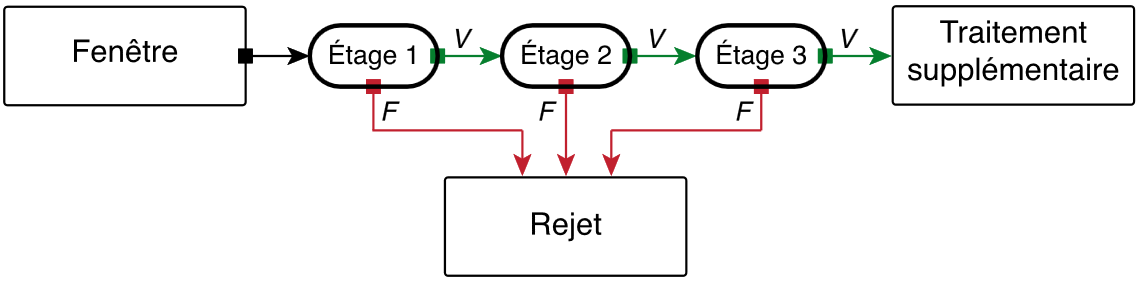
Ainsi dès que l'un des étages estime qu'il n'y a pas de visage, la fenêtre est rejetée et l'algorithme passe à la suite ce qui permet un gain de temps considérable.
Voilà vous savez tout ! Piouf, ça en fait des informations ! Allez, comme je suis sympa je vous ai fais un beau schéma fonctionnel de l'algorithme :

2. Installation des librairies OpenCV
2.1 Pour Linux
Nous arrivons maintenant à la partie la plus rébarbative (pour rester poli) de ce tuto, à savoir, l'installation des librairie OpenCV.
Comme je vous l'ai dis dans l'introduction, vous devez posséder un poste avec Linux d'installé. Dans mon cas j'ai utilisé la dernière version de Ubuntu disponible.
Commençons par ouvrir un terminal. Nous allons d'abord nous assurer que tout notre système est à jour :
sudo apt-get update
sudo apt-get upgrade
Ensuite, on passe à l'installation de build-essential :
sudo apt-get install build-essential
Ensuite, téléchargez les sources.
Choissiez la dernière version. Il s'agit d'une archive qu'il faut extraire.
Une fois l'archive extraite, placez vous dans le répertoire obtenu :
cd ~/Téléchargements/OpenCV-2.3.1
Ensuite, nous allons créer un répertoire de compilation et nous placer dedans :
mkdir rep_compil
cd rep_compil
Maintenant que c'est fait, nous allons lancer la commande Cmake en utilisant ../ qui permet de remonter d'un niveau dans l'arborescence :
sudo cmake ../
Si le retour de console vous dit que la commande "cmake" n'existe pas, vous pouvez l'installer en tapant la commande : sudo apt-get install cmake
Maintenant, nous allons lancer la compilation :
sudo make
Après quelques dizaines de minutes, vous devriez obtenir :
Pour finaliser l'installation :
sudo make install
Maintenant, il faut éditer le fichier opencv.conf :
sudo gedit /etc/ld.so.conf.d/opencv.conf
La modification consiste à ajouter la ligne suivante : /usr/local/lib
Enregistrez et fermez. Ensuite, il faut lancer la ligne de configuration de librairie :
sudo ldconfig
Et enfin, il faut éditer le ficher bash.bashrc :
sudo gedit /etc/bash.bashrc
et ajouter les lignes suivante :
#-------- opencv ----
PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/usr/local/lib/pkgconfig
export PKG_CONFIG_PATH
Enregistrez, quittez/relancez un terminal pour que les chemins indiqués soient pris en compte.
Normalement, c'est tout bon pour l'installation d'openCV !
2.2 Pour Windows
Pour ceux qui utilisent Windows, voici un très bon tutoriel qu'un lecteur m'a proposé.
3. Implémentation de l'algorithme en C++
Vous avez maintenant toutes les cartes en main pour commencer l'implémentation de l'algorithme de détection de visage.
Commencez par télécharger le classifieur qui va nous permettre de déterminer si un visage est présent dans une fenêtre de détection ou non. Il s'agit d'un fichier .xml.
Maintenant, nous allons nous créer un répertoire de travail propre, créez donc un répertoire sur le bureau, par exemple "faceDetect" et placez-y le classifieur. Maintenant, créez un fichier "faceDetect.cpp", ouvrez-le avec un éditeur de texte (Gedit par exemple) et passons tout de suite au codage.
Commençons par le commencement : les includes
#include <opencv/cv.h>
#include <opencv/highgui.h>
#include <stdio.h>
Ensuite, on déclare des variables globales et notre fonction de détection :
/*------ Declaration des variables globales ------*/
char key;
CvHaarClassifierCascade *cascade;
CvMemStorage *storage;
/*---------- Declaration des fonctions -----------*/
void detectFaces(IplImage *img);
La variable key va nous servir à détecter la touche Q du clavier pour arrêter le programme quand nous le souhaiterons.
La variable cascade contiendra notre classifieur. On le devine assez facilement en regardant le type de la variable.
La variable storage, quant à elle, va nous servir à définir l'espace mémoire utilisé pour le traitement du flux vidéo.
Pour le moment, on ne fait que déclarer la fonction detectFaces(), nous l'écrirons un peu plus tard.
Ensuite arrive la fonction main() dans laquelle tout va se passer. Tout d'abord nous allons déclarer quelques variables.
void main(void)
{
/* Declaration des variables */
CvCapture *capture;
IplImage *img;
const char *filename = "/home/lobodol/Bureau/faceDetect/haarcascade_frontalface_alt.xml";
}
La variable capture correspond au flux vidéo récupéré par la webcam. C'est ce flux que l'on va transmettre à notre fonction de détection de visage.
img n'est rien d'autre que l'image à un instant t du flux vidéo.
La variable filename est un pointeur de caractères pointant sur l'emplacement où est enregistré votre classifieur. Ici on voit qu'il est enregistré dans "/home/lobodol/Bureau/faceDetect/haarcascade_frontalface_alt.xml";
Nous allons maintenant initialiser tout ce petit monde :
/* Chargement du classifieur */
cascade = (CvHaarClassifierCascade*)cvLoadHaarClassifierCascade( filename, cvSize(24, 24) );
/* Ouverture du flux video de la camera */
capture = cvCreateCameraCapture(CV_CAP_ANY);
/* Initialisation de l’espace memoire */
storage = cvCreateMemStorage(0);
/* Creation d’une fenetre */
cvNamedWindow("Window-FT", 1);
Comme vous pouvez le voir, nous chargeons notre classifieur grâce à la fonction cvLoadHaarClassifierCascade à laquelle nous passons en argument la variable filename qui contient le chemin vers note classifieur au format .xml. Le second paramètre, cvSize(24, 24), correspond à la taille initiale de la fenêtre de détection, soit ici 24px par 24px.
On ouvre ensuite le flux vidéo en utilisant CV_CAP_ANY comme argument de la fonction cvCreateCameraCapture ce qui signifie en gros "la première webcam disponible". La fonction va donc ouvrir un flux vidéo sur notre webcam. Le flux vidéo est enregistré dans la variable capture déclarée précédemment.
On initialise l'espace mémoire et on créé une fenêtre nommée "Window-FT" qui servira à afficher le résultat.
Si vous rencontrez des difficultés avec votre webcam, sachez que vous pouvez utiliser un fichier vidéo comme flux vidéo. Il faudra alors utiliser : capture = cvCreateFileCapture("/chemin/vers/votre/video.avi"); à la place.
Passons maintenant à la boucle de traitement dans laquelle nous allons effectuer la détection de visage sur chaque frame.
/* Boucle de traitement */
while(key != 'q')
{
img = cvQueryFrame(capture);
detectFaces(img);
key = cvWaitKey(10);
}
Comme je vous l'ai dis au début de ce chapitre, nous voulons arrêter le processus lorsqu'on appuie sur la touche Q, la condition de boucle est donc, "tant que la touche ne vaut pas Q".
On stocke l'image en cours du flux vidéo dans la variable img déclarée plus haut. Cette image est ensuite passée à la fonction detectFaces() que nous allons écrire tout de suite après.
Enfin, le programme attend pendant 10ms pour voir si on a appuyé sur une touche du clavier.
C'est tout pour la boucle de traitement !
Passons maintenant au coeur du sujet : la fonction detectFaces().
void detectFaces(IplImage *img)
{
/* Declaration des variables */
int i;
CvSeq *faces = cvHaarDetectObjects(img, cascade, storage, 1.1, 3, 0, cvSize(40,40));
for(i=0; i<(faces?faces->total:0); i++)
{
CvRect *r = (CvRect*)cvGetSeqElem(faces, i);
cvRectangle(img, cvPoint(r->x, r->y), cvPoint(r->x + r->width, r->y + r->height), CV_RGB(255, 0, 0), 1, 8, 0);
}
cvShowImage("Window-FT", img);
}
Oh la la, qu'est-ce que c'est que cette fonction ... ?
Pas de panique, nous allons voir ça en détail.
Tout d'abord, nous récupérons l'image passée en argument. C'est sur cette image que les traitements sont effectués. Les librairies OpenCV intègrent déjà la méthode de Viola & Jones, il devient donc très facile de l'utiliser. Tout repose sur la fonction cvHaarDetectObjects() à laquelle nous passons en argument notre image, notre classifieur, l'espace mémoire défini précédemment et quelques paramètres que nous allons démystifier :
- 1.1 correspond au scale factor (facteur d'échelle)
- 3 correspond au nombre de voisins minimum
- 0 est un paramètre supplémentaire qui permet de rajouter des filtres particuliers, par exemple un filtre de canny avec CV_HAAR_DO_CANNY_PRUNING
- cvSize(40,40) correspond à la taille minimale de la fenêtre de détection
Si le rendu de votre vidéo est "lent", vous pouvez augmenter la taille de la fenêtre afin d'augmenter la rapidité de traitement. Par exemple passer à cvSize(100,100). De manière générale, vous pouvez jouer avec ces paramètres afin d'optimiser votre programme.
Le résultat retourné par cette fonction est une série d'objets qui ont passé les critères de sélection définis par le classificateur. On définit donc une CvSeq qui correspond à une séquence d'objet d'un même type, dans notre cas il s'agi nos différents visages détectés.
Ensuite, nous allons simplement dessiner des rectangles là où des visages ont été détectés. Pour ça, on utilise une boucle for qui passe en revue tous les visages détectés pour une frame et dessine un rectangle autour.
Enfin, il ne reste plus qu'à afficher tout ça grâce à la fonction cvShowImage() à laquelle on passe en argument le nom de notre fenêtre créée précédement et notre image "rectanglisée".
Pas si compliqué que ça finalement, si ?
Comme nous sommes en C++, il nous reste une dernière chose à faire : libérer la mémoire lorsque l'on quitte le programme. On place donc ces quelques lignes à la fin de notre main :
/* Liberation de l’espace memoire*/
cvReleaseCapture(&capture);
cvDestroyWindow("Window-FT");
cvReleaseHaarClassifierCascade(&cascade);
cvReleaseMemStorage(&storage);
return 0;
Ca y est c'est terminé ! Finalement, nous obtenons le code complet suivant :
/*------------------------------------------------*/
#include <stdio.h>
#include <opencv/cv.h>
#include <opencv/highgui.h>
#include <opencv/cxcore.h>
/*------ Declaration des variables globales ------*/
char key;
CvHaarClassifierCascade *cascade;
CvMemStorage *storage;
/*---------- Declaration des fonctions -----------*/
void detectFaces(IplImage *img);
/*------------------------------------------------*/
int main(void)
{
/* Declaration des variables */
CvCapture *capture;
IplImage *img;
const char *filename = "/home/lobodol/Bureau/faceDetect/haarcascade_frontalface_alt.xml";
/* Chargement du classifieur */
cascade = (CvHaarClassifierCascade*)cvLoadHaarClassifierCascade( filename, cvSize(24, 24) );
/* Ouverture du flux video de la camera */
capture = cvCreateCameraCapture(-1);
// Ouverture d'un fichier video
//capture = cvCreateFileCapture("/home/lobodol/Telechargements/cam.avi");
/* Initialisation de l'espace memoire */
storage = cvCreateMemStorage(0);
/* Creation d'une fenetre */
cvNamedWindow("Window-FT", 1);
/* Boucle de traitement */
while(key != 'q')
{
img = cvQueryFrame(capture);
detectFaces(img);
key = cvWaitKey(10);
}
/* Liberation de l'espace memoire*/
cvReleaseCapture(&capture);
cvDestroyWindow("Window-FT");
cvReleaseHaarClassifierCascade(&cascade);
cvReleaseMemStorage(&storage);
return 0;
}
/*------------------------------------------------*/
void detectFaces(IplImage *img)
{
/* Declaration des variables */
int i;
CvSeq *faces = cvHaarDetectObjects(img, cascade, storage, 1.1, 3, 0, cvSize(40,40));
for(i=0; i<(faces?faces->total:0); i++)
{
CvRect *r = (CvRect*)cvGetSeqElem(faces, i);
cvRectangle(img, cvPoint(r->x, r->y), cvPoint(r->x + r->width, r->y + r->height), CV_RGB(255, 0, 0), 1, 8, 0);
}
cvShowImage("Window-FT", img);
}
Cette fois, il ne nous reste plus qu'à compiler et exécuter !
Ouvrez un terminal, placez-vous dans votre répertoire de travail et tapez la commande suivante pour compiler :
g++ -o faceDetect faceDetect.cpp `pkg-config --cflags --libs opencv`
Et on exécute :
./faceDetect
Bravo vous avez réussi à implémenter la méthode de détection de visage de Viola & Jones ;)
Ne vous découragez pas si vous n'y arrivez pas du premier coup, il s'agit d'un sujet complexe et c'est normal d'éprouver des difficultés au début. Quoi qu'il en soit, si vous avez des questions, n'hésitez pas à me contacter !
A bientôt sur fire-DIY !
Autres articles dans la catégorie Informatique :



Vos réactions (0) :
- Sois le/la premier(e) à commenter cet article !